따라 하며 배우는 데이터 과학 - 파이썬 편 1 - 환경 설정
왜 파이썬인가?
“따라 하며 배우는 데이터 과학”은 R에 초점을 맞추었다. 하지만 책 초반에 언급하였듯이, 중급 이상의 데이터 과학자라면 파이썬도 사용할 줄 알아야 한다:
… 복잡한 데이터 가공과 자동화 작업에 인기 있는 언어는 파이썬이다. 파이썬은 많은 회사에서 데이터 과학뿐 아니라 C/C++, Java 등 처럼 웹서버와 백엔드 시스템 프로그래밍에도 사용되는 ‘진짜’ 프로그래밍 언어다. 배우기 쉽고 가독성이 높은 코드 덕분에 프로그래밍 교육에도 많이 쓰인다.
사실, 데이터 가공과 자동화뿐 아니라 데이터 분석, 시각화까지 모든 데이터 과학 작업을 R 없이 파이썬만으로 할 수 있다! 실리콘밸리의 데이터 과학자 중 실제로 R을 거의 사용하지 않는 사람도 많이 보인다. 보통 (저자처럼) 통계학에서 출발한 사람들은 R이 더 익숙하고, 필요하면 파이썬을 사용한다. 통계학이 아닌 컴퓨터공학 등의 다른 전공에서 출발한 사람들은 파이썬을 선호하는 경향이 있다.
파이썬은 크고 방대하므로 이 장에서 다루지 않겠다. 하지만 중급 이상의 데이터 과학자가 되려면 꼭 배워두도록 하자. 일단 데이터가 준비되면 R에서 대부분의 작업을 할 수 있지만 데이터 취득, 데이터 가공(특히 큰 데이터!), 자동화 등에서 파이썬을 사용하면 훨씬 효율적이고 쉽게 작업할 수 있는 것들이 많다.
— “따라하며 배우는 데이터 과학”(2017) (48페이지)
이번 시리즈에서는 “따라하며 배우는 데이터 과학”의 내용을 기반으로 파이썬 사용법을 배워보도록 하자.
예제는 맥 OS X 환경 중심으로 설명하겠지만, 큰 문제 없이 윈도우즈나 리눅스 환경에서도 실행할 수 있다.
파이썬 데이터 과학 환경 설정
아나콘다(anaconda)로 파이썬과 중요 패키지 설치
파이썬을 시스템에 설치하는 다양한 방법이 있지만, 필자가 추천하는 방법은 아나콘다(anaconda) 배포판을 사용하는 것이다. 아나콘다 배포판은 맥, 윈도우즈, 리눅스 등 여러 OS를 지원하고, 파이썬 버전 2.7이나 3.x 모두를 지원하며, 데이터과학에 많이 사용되는 핵심 패키지(주피터, 판다스, 넘파이 등)를 기본적으로 설치해 주고, 파이썬 패키지의 깔끔한 관리를 돕는다. 아나콘다 다운로드 페이지 https://www.anaconda.com/download/에서 본인의 OS에 해당하는 배포판을 다운로드하여 설치한다.
파이썬 2.7 혹은 3.6?
아나콘다 웹페이지에는 각 OS별로, 파이썬 2.7이나 3.6을 다운로드할 수 있다. 어떤 버전을 사용해야 할까? 현재 파이썬의 공식적 입장은 “조만간, 웬만하면, 3.x을 사용하라”이다. 하지만, 아직도 파이썬 2.7이 널리 사용되고 있고, 2018년 현재 데이터 분석 작업에는 파이썬 2.7을 사용하여도 전혀 문제가 없으므로, 본서에서는 파이썬 2.7을 사용하도록 한다. (예제 코드들은 약간만 바꿔주면 파이썬 3.x 에서도 돌아간다.)
파이썬 셸
파이썬 설치 후 터미널에서 다음처럼 파이썬 셸(python shell)을 시작해보자. (파이썬 셸에서 Ctrl+D 를 누르면 터미널로 빠져나온다.)
$ python
Python 2.7.10 (default, Jul 15 2017, 17:16:57)
[GCC 4.2.1 Compatible Apple LLVM 9.0.0 (clang-900.0.31)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>>
파이썬 셸 안에서도 인터랙티브하게 파이썬을 실행할 수 있지만, 본서는 주로 파이썬 셸 대신 주피터 노트북을 사용할 것이다.
주피터 노트북 사용
주피터 노트북(Jupyter Notebook)은 실행 가능한 코드와 수식, 시각화와 텍스트를 포함한 문서를 작성하는 브라우저 기반 환경이다. 아나콘다에는 이미 설치되어 있다.
주피터 노트북 환경 준비와 시작
주피터 노트북을 실행하려면, 작업 디렉토리에서
터미널로 jupyter notebook 명령을
실행하면 된다.
독자가 깃(Git)/깃허브(Github) 사용법에 익숙하다면,
깃헙의 “따라 하며 배우는 데이터 과학” (2017) 소스코드 리포(https://github.com/jaimyoung/ipds-kr)를 깃-클론한 디렉토리에서 시작하는 것을
가정하겠다. 예를 들어 독자의 개별 프로젝트를
~/projects/ 하위 폴더로 관리한다고 하면,
다음 터미널 명령으로 리포를 클론하고, 클론된 디렉토리로 이동하자:
$ cd ~/projects/
$ git clone git@github.com:jaimyoung/ipds-kr.git
$ cd ipds-kr/
본서의 예제 주피터 노트북들은 위에서 이동한
ipds-kr 리포/디렉토리의 notebooks 하위 디렉토리에 저장되어 있다.
다음 명령으로 이 노트북 폴더에서 주피터를 시작하자:
$ cd notebooks
$ jupyter notebook
명령실행 후 브라우저에 다음과 같은 화면이 뜬다면 성공이다:
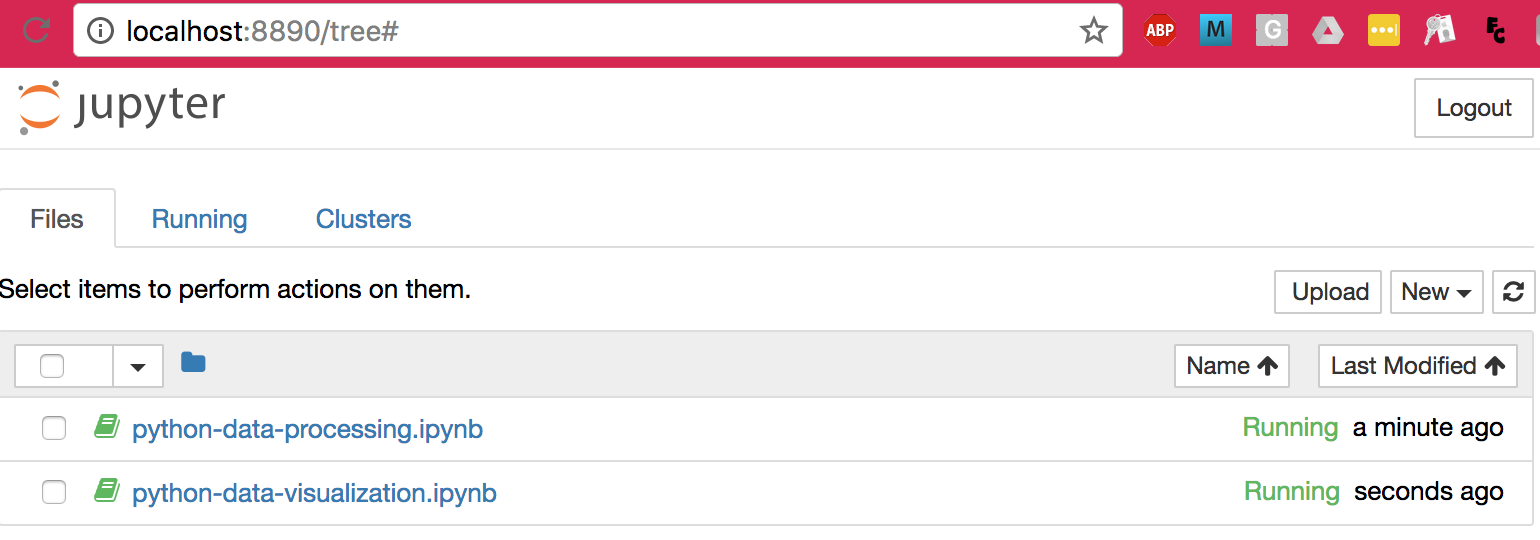
그림 — 주피터 노트북 초기 화면
새로운 파이썬 노트북 시작
초기 화면의 오른쪽 “New” 를 클릭한 후 드롭다운 메뉴에서 아래 그림처럼 “Python 2”을 선택하면 비어있는 새 파이썬 노트북이 만들어진다:
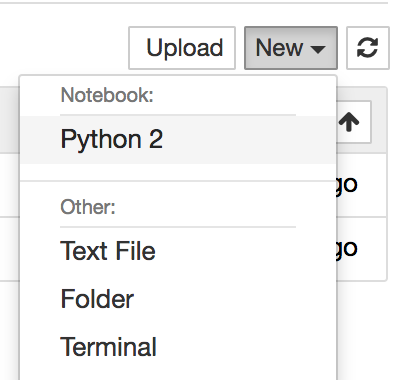
그림 — 새로운 노트북 생성하기
새로운 노트북은 다음과 같은 모양이다.
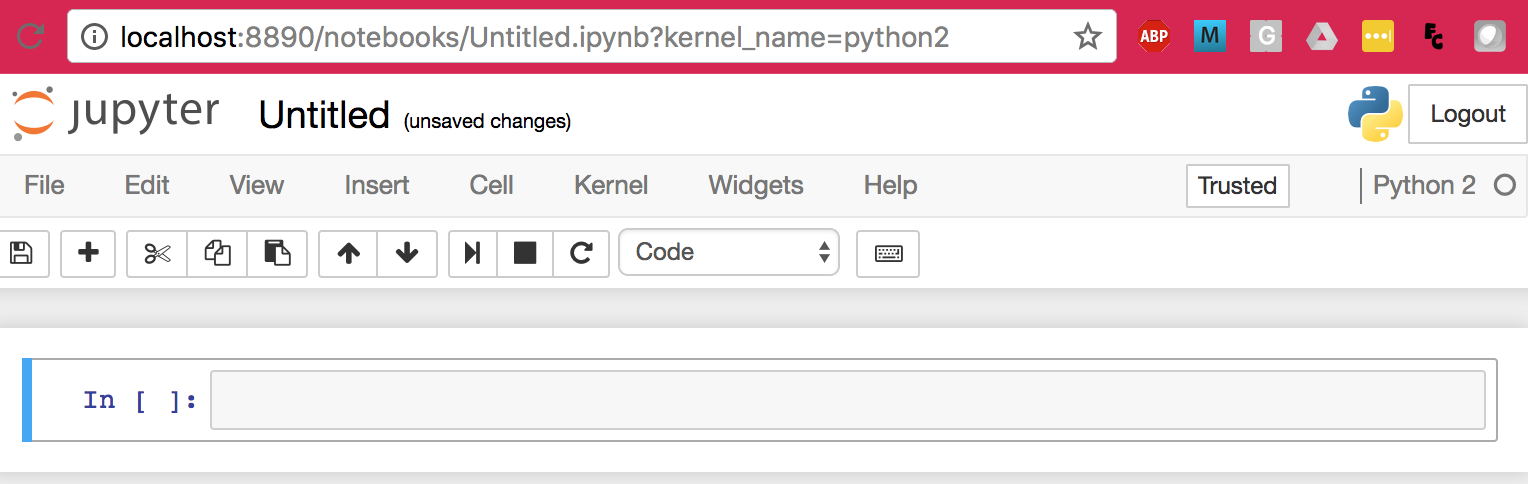
그림 - 새로운 노트북
파이썬 명령 입력과 실행
초기 화면은 명령 모드(command mode)에서 시작한다.
In []: 옆의 빈 셀(cell)을 클릭하면 편집모드(edit mode)로 들어가서 셀 내용을 편집할 수 있다.
편집모드에서 첫째 셀에
다음 파이썬 코드를 복사하여 붙여넣자:
%matplotlib inline
import pandas as pd
import numpy as np
gapminder_r_url = "https://raw.githubusercontent.com/jennybc/gapminder/master/data-raw/07_gap-merged-with-continent.tsv"
gapminder = pd.read_csv(gapminder_r_url, sep="\t")
gapminder.shape
붙여넣은 후,
Shift+Enter 를 누르면
gapminder 자료가 다운로드되어서 읽혀지고,
자료의 차원이 표시된다:
(3313, 6) 즉, 3313 행 (관측치), 6 열 (변수)이다.
그리고, 현재 셀 아래에 새로운 셀이 추가되어 다음 입력을 기다리게 된다.
다음 셀에 다음 명령을 붙여 넣고 앞서와 마찬가지로 Shift+Enter를 누르면
gapminder 자료의 첫 5줄을 표시해준다:
gapminder.head()
그 다음 셀에는 다음 명령을 붙여 넣고 Ctrl+Enter를 눌러보자. (실행은 되지만, Shift+Enter 와는 달리 다음 셀이 추가되지 않는다.)
gapminder.lifeExp.plot.hist()
지금까지 연습 결과가 다음 화면처럼 되면 성공이다:
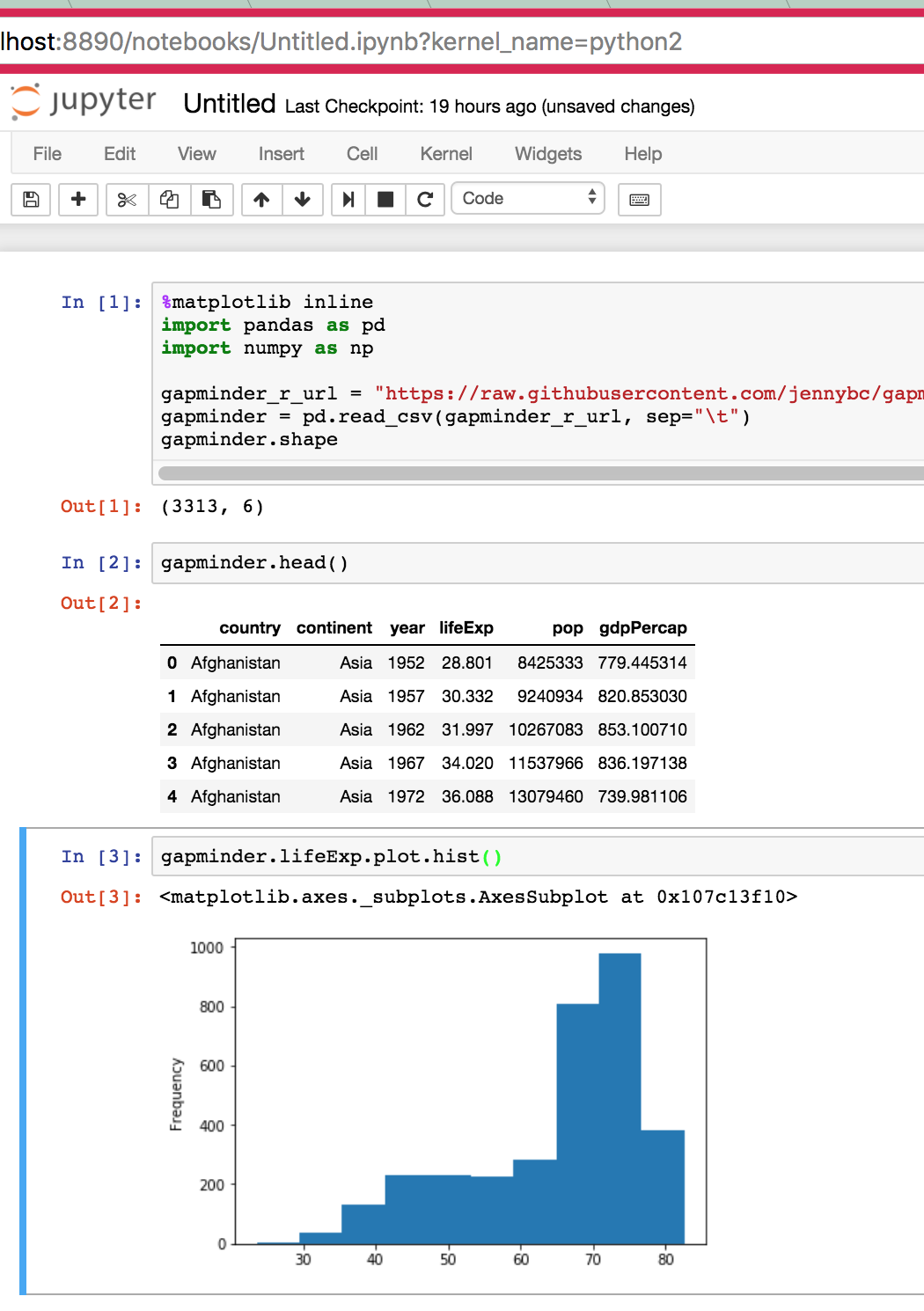
그림 - session-01 결과
노트북 저장, 주피터 종료와 재시동
앞서 작성한 노트북의 제목/파일 이름은 Untitled이다.
노트북의 File > Renam… 메뉴를 클릭하고
session-01를 입력하여 이름을 변경하자.
이름을 변경하면 현재 작업 디렉토리에
session-01.ipynb 파일이 생성되었음을 알 수 있다:
$ ls -l
session-01.ipynb
주피터를 종료하기 위해서는 앞서 jupyter notebook으로
주피터를 시작한 셀 세션으로 돌아가서 Ctrl+C 를 두 번 눌러주면 된다:
$ jupyter notebook
...
[I 18:21:57.941 NotebookApp] The Jupyter Notebook is running at: http://localhost:8890/?token=dd6a9dbc628684ad50d38100ceec825395cb430bcc710c46
[I 18:21:57.941 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
...
# Ctrl+C 를 두 번 눌러준다
[I 14:54:04.279 NotebookApp] Shutting down kernels
[I 14:54:04.690 NotebookApp] Kernel shutdown: 4528f802-71ab-4ce2-9cc1-bad03e2d88ee
$
jupyter notebook 을 다시 시작하고,
아까 작성한 session-01 파이썬 노트북을 클릭하면
이전에 작업한 노트북을 다시 열게 된다.
노트북의 내용은 그대로이지만,
새로운 파이썬 세션이므로, gapminder 변수를 사용하려면
노트북의 코드를 다시 실행해야 함을 기억하자.
Kernel -> Restart & Run All
명령을 사용하면 간편하다.
그림 - 주피터 재시작
명령모드와 편집모드, 중요 키보드 단축키, 팁
주피터 노트북은 아무 때나 Esc 키를 누르면 명령모드(command mode)로 들어가고 Enter 키나 셀을 클릭하면 편집모드(Edit mode)로 들어가게 된다.
필자의 경험상 핵심적인 키보드 단축키는 다음과 같다:
- 공통
- Shift + Enter : run cell, select below
- Ctrl + Enter : run selected cells
- Esc : Enter command mode
- Enter : Enter edit mode
- ⌘ + Shift + P : Show command palette
- 명령모드 (grey cell border with a blue left margin)
- Y / M : Change cell type to code / markdown
- Shift + ↑/↓ : Extend cell selections
- Shift + M : Merge selected cells, or merge the current cell with the one below
- D,D : delete selected cells
- C / X / V : copy / cut / paste below
- A / B : add cell above / below
- 편집모드 (green cell border)
- Tab : Code completion
- Shift + Tab : Python tooltip
- Shift + Tab (twice) : Detailed Python tooltip
파이썬 패키지 관리와 설치
아나콘다 버전확인과 설치된 패키지를 확인하려면 다음 명령을 실행하면 된다. 주피터, 넘파이, 판다스가 기본적으로 설치된 것을 확인할 수 있다:
$ conda --version
conda 4.4.7
$ conda list
# packages in environment at /Users/jaimiekwon/anaconda2:
#
_ipyw_jlab_nb_ext_conf 0.1.0 py27h172cb35_0
alabaster 0.7.10 py27h9dd7d6e_0
anaconda custom py27h2cfa9e9_0
...
jupyter 1.0.0 py27hec63c99_0
numpy 1.13.3 py27h62f9060_0
pandas 0.20.3 py27h2a3d8ca_2
많은 경우에 conda 대신 일반적인 파이썬 패키지 관리 툴인 pip를 사용하면 된다.
즉 conda list 대신에, pip list 를 사용한다:
$ pip list
alabaster (0.7.10)
...
jupyter-client (5.1.0)
numpy (1.13.3)
pandas (0.20.3)
...
아직 설치되지 않은 패키지를 추가하기 위해서는 pip install 명령을 사용한다.
예를 들어, geopandas 와 folium 패키지를 설치하기 위해서는:
$ pip install geopandas folium
팁: 슈퍼유저로 sudo pip install 실행하지 말기!
(유닉스/맥 전문가에게만 적용되는 이야기입니다)
아나콘다 환경에서 패키지를 설치할 때 조심할 것은
절대 슈퍼유저 권한으로 sudo pip install 을 실행하지 말라는 것이다.
아나콘다는 운영체제의 파일을 최대한 건들지 않고
깔끔하게 사용자 디렉토리
(Users/$username/anaconda2/)만을 사용하는 것을 지향하기 때문이다.
팁: 패키지 버전 판다스/넘파이
2018년 1월 현재 https://pandas.pydata.org/pandas-docs/stable/ 에 따르면 판다스의 안정적인 (stable) 최신 버전은 0.22.0 이다. API 가 계속 바뀌고 있으므로, 전에 작동하던 코드가 동작하지 않던가 할 수 있다.
참고 문헌
연습 문제
- 아나콘다 파이썬을 설치한 후, 주피터 노트북에서 다음 처리를 해 보자.
- 판다스 패키지를
pd란 이름으로 로드한다. pd.read_로 시작하는 함수는 몇가지나 되는가?pd.read_csv()함수의 인자는 무엇이 있는가? (힌트: Shift + Tab)pd.read_csv()함수로 탭 구분된 자료를 읽어들이는 방법은?
- 판다스 패키지를
- 다음 라이브러리를 설치하여 보라.
- 그래프 알고리즘을 위한 https://networkx.github.io/documentation/stable/
- 위 라이브러리를
nx란 이름으로 로드하라 - 매뉴얼의 shortest path algorithm 예제를 실행해 보라
연습문제 해답:
- 판다스 문제:
import pandas as pd- 18가지
- 수십가지 인자가 있다! 온라인 매뉴얼을 봐도 되지만 (https://pandas.pydata.org/pandas-docs/stable/generated/pandas.read_csv.html) 주피터 안에서 간편하게 볼 수 있다는 것이 장점.
sep='\t'인자를 사용하면 된다.
- networkx
-
https://networkx.github.io/documentation/stable/install.html 에 써 있는 대로,
pip install networkx을 실행하면 된다. 물론 https://anaconda.org/anaconda/networkx에 나온데로, 콘다(conda)를 이용해 설치해도 된다.
- notebook에서 다음 명령이 실행되면 성공:
import networkx as nx - 다양한 알고리즘이 있지만 https://networkx.github.io/documentation/networkx-1.10/reference/generated/networkx.algorithms.shortest_paths.generic.shortest_path.html#networkx.algorithms.shortest_paths.generic.shortest_path 정도를 실행하면 성공.
-